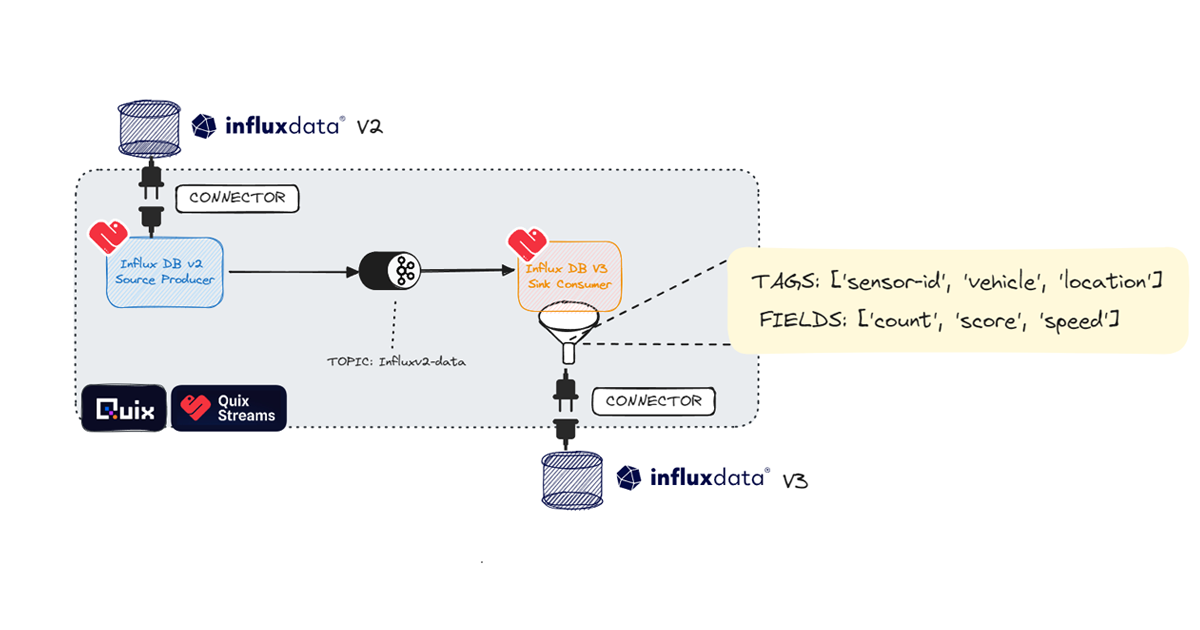
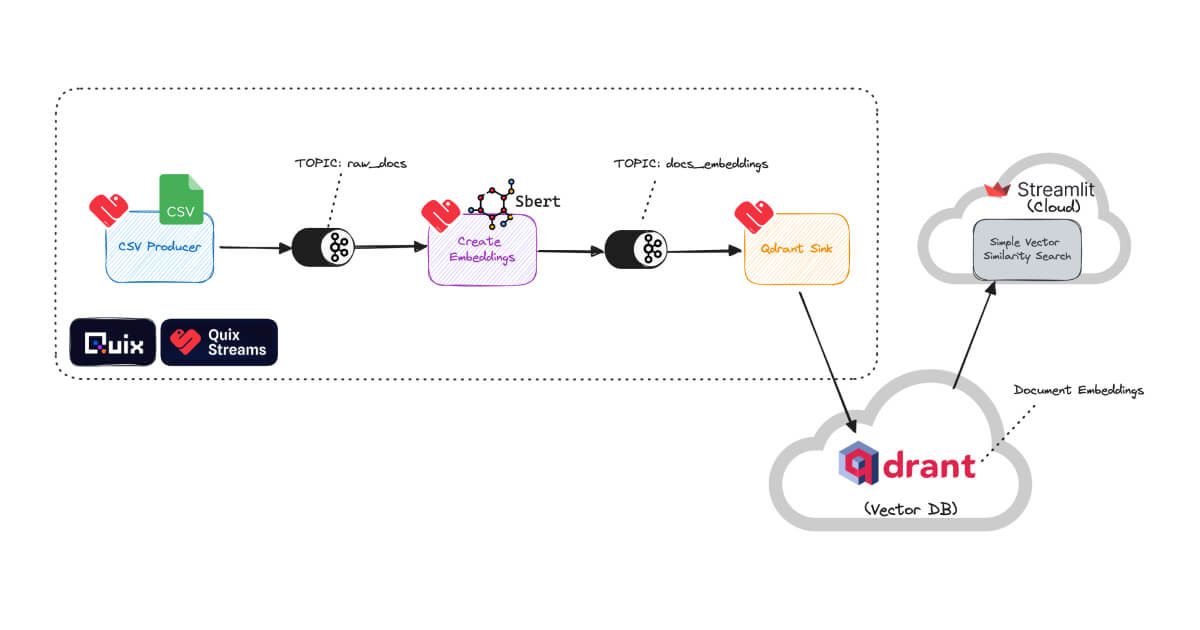
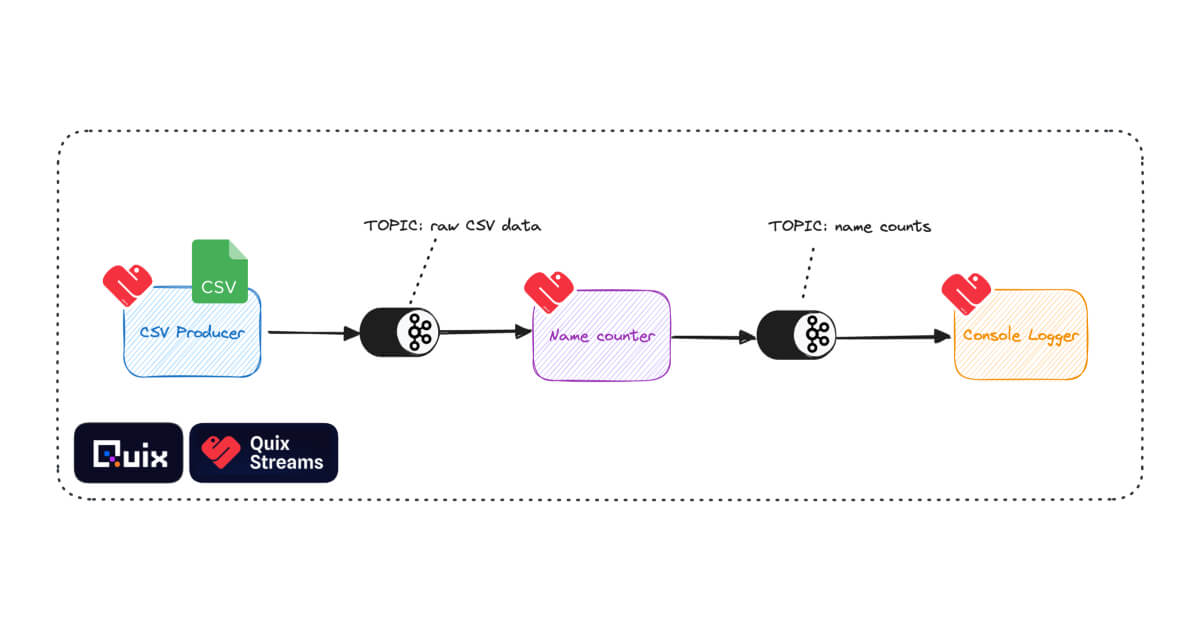
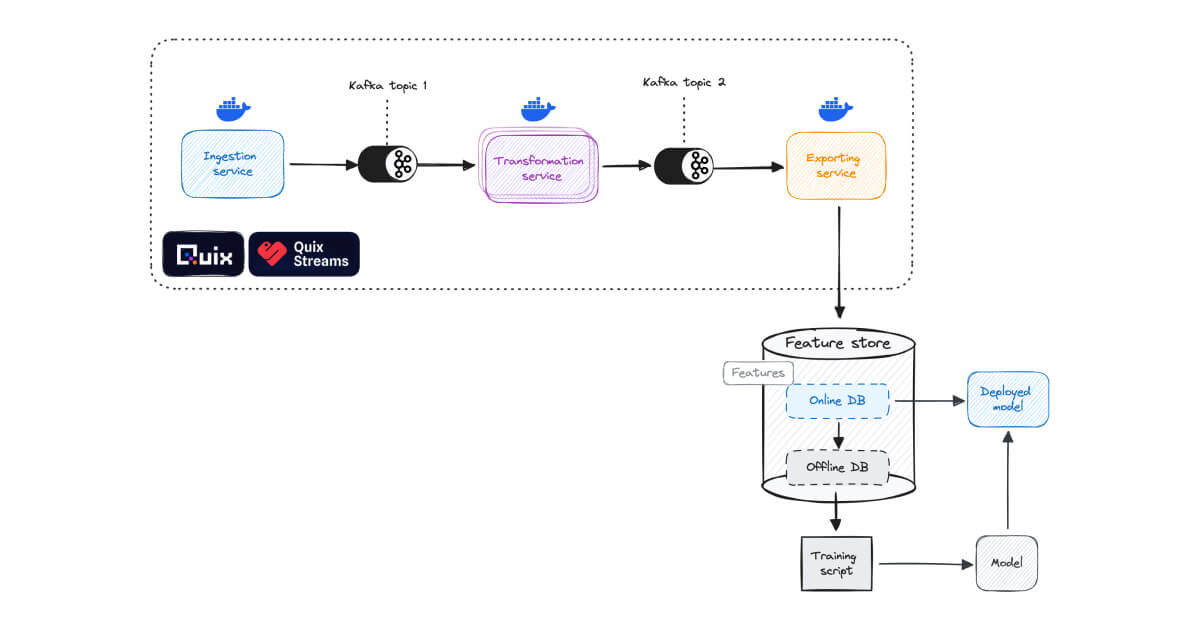
Build streaming data pipelines easily

Pure Python
No JVM. No wrappers. No cross-language debugging or complex abstraction layers. Use any package from the entire Python ecosystem.

DataFrame API
Treat data streams as continuously updating tables. Ideal for transitioning projects from Pandas or PySpark.

Flexible
No JAR files. Quix leverages Docker to simplify dependency management for stream processing pipelines.

Stateful operators
Use built-in hopping and tumbling window functions to build stateful calculations with fewer lines of code.

Scalable
Designed for efficient scaling, Quix leverages Kafka and Kubernetes to provide data partitioning, consumer groups, state management, and replication.

Fault tolerant
Guarantees reliable data delivery and robust failure recovery through data replication, service replication, changelogs and checkpointing.